
Financial Article Categoriser

Introduction
This was a data science project working with a client. The client is a company that specialises in financial products comparison like home loans, credit cards, superannuation etc. To spread awareness of the various products managed by them, they place the products on websites that show mostly articles like news, blogs etc.
My objective here was to develop a model that will be able to read an article to automatically label which financial product was the closest to place near/next to a article.
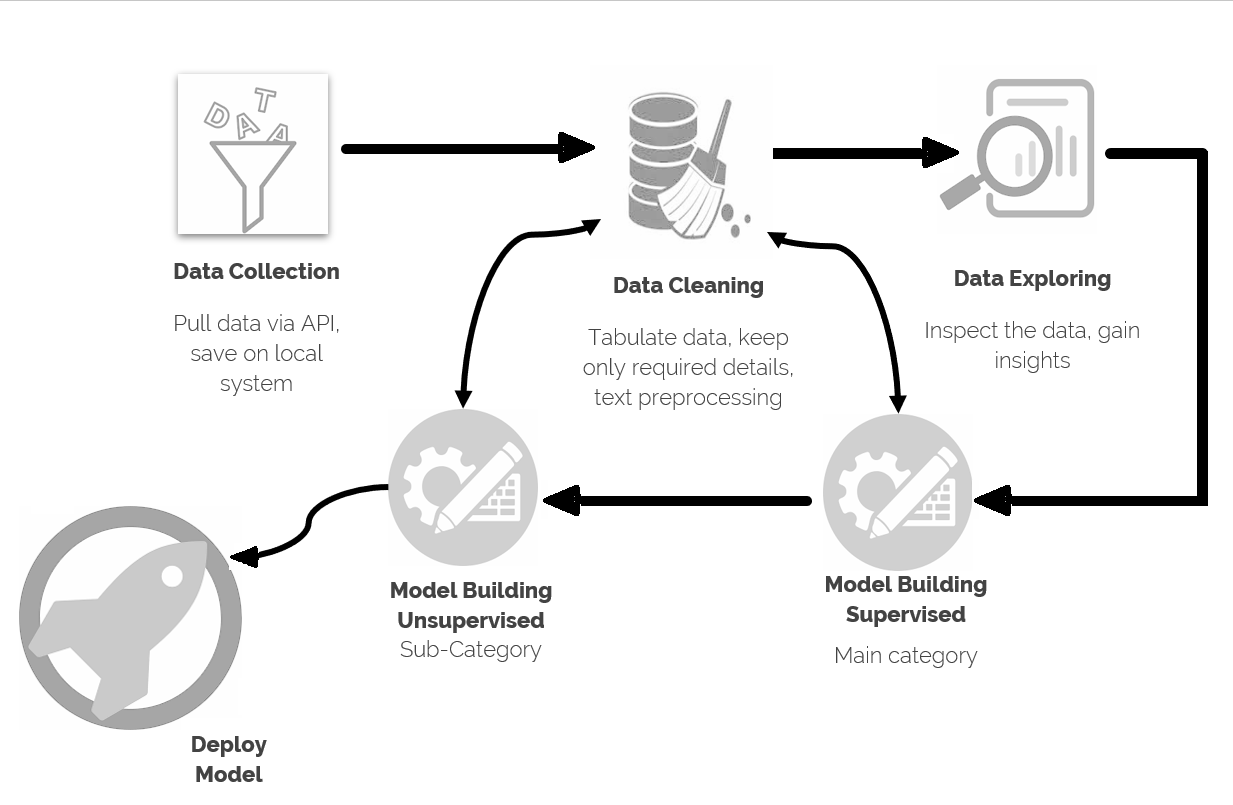
Project Workflow
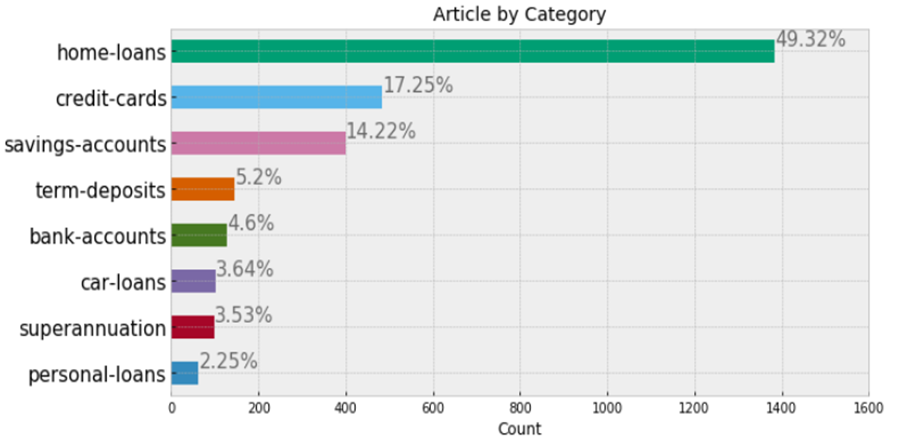
The Dataset
The client has been publishing their own financial articles which they have already labelled appropriately based on the context and collected. I was given access to this dataset via API. I wrote a code in python to pull all the labelled articles into my local system. There were 8 required categories:
- Home-Loans
- Personal-Loans
- Car-Loans
- Credit Cards
- Superannuation
- Savings Accounts
- Term Deposits
- Bank Accounts
Total articles: 2813
Using this dataset, I built a classifier that learnt from this dataset and predicted the category on new articles from external sources.
Natural Language Processing
Since the data is text, I used Natural Language Processing (NLP). Simply put it’s a process that helps in conversion of text as we humans understand it into numerical representation that the machine learning model understands.

Text Pre-processing/Cleaning
The above will find some numerical representation for every word. However, this won’t be useful as some words will appear commonly in all the categories and don’t contribute to the classification. I removed such words. Other steps followed to clean up the text,
- Removed contractions
- Removed numbers
- Removed junk words
The steps above will vary from project to project. I would try and fit a model for each cleaning step to check for improvement in performance.
Exploring the Categories
After the cleaning I looked at the top word, two-word combo in each category. Below is two-word combo bar plot for 4 of the categories
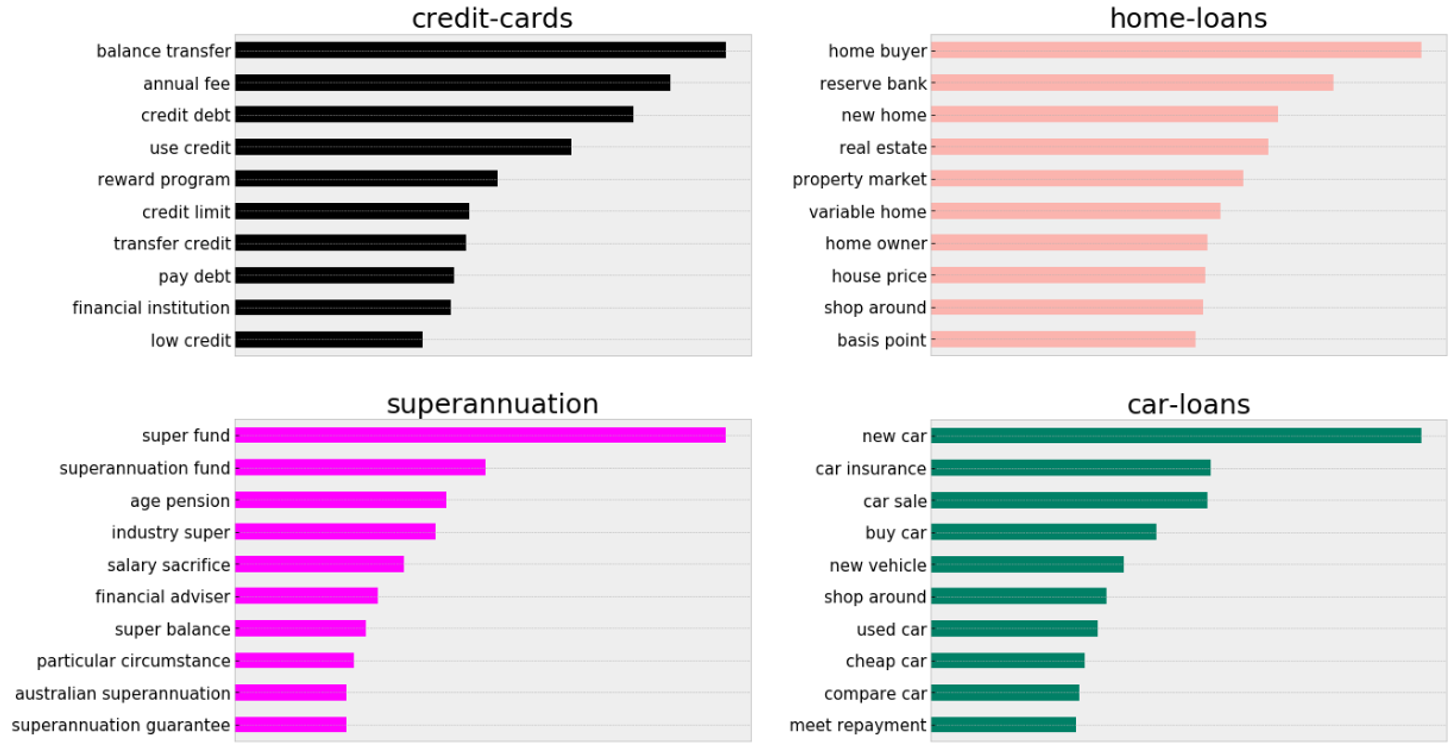
The distinction in words was good at this stage. I was quite satisfied with this and proceeded from here to build the model.
Wordcloud
Wordcloud is a more interesting way to visualise word representation for each category.
HOME LOANS

CAR LOANS
Model Building
After testing different types of classifier models and checking for accuracy, the best performing model was Logistic Regression. The accuracy was compared to the baseline score.
Baseline score: For example, if you had a set of true and false questions, 60% of correct answers were true and you answered all true you’ll get 60% right. Basically you didn’t do any work you just chose the majority answer therefore you performed at baseline level.
So in my case if you look at the chart below,
Majority Class: Home-Loans
Baseline Accuracy: 50%
Model Accuracy: 92%
Confusion Matrix (Model Evaluation)
Confusion matrix helps to see where the model went wrong.
Along the vertical are the actual labels
Along the horizontal are the model predicted labels
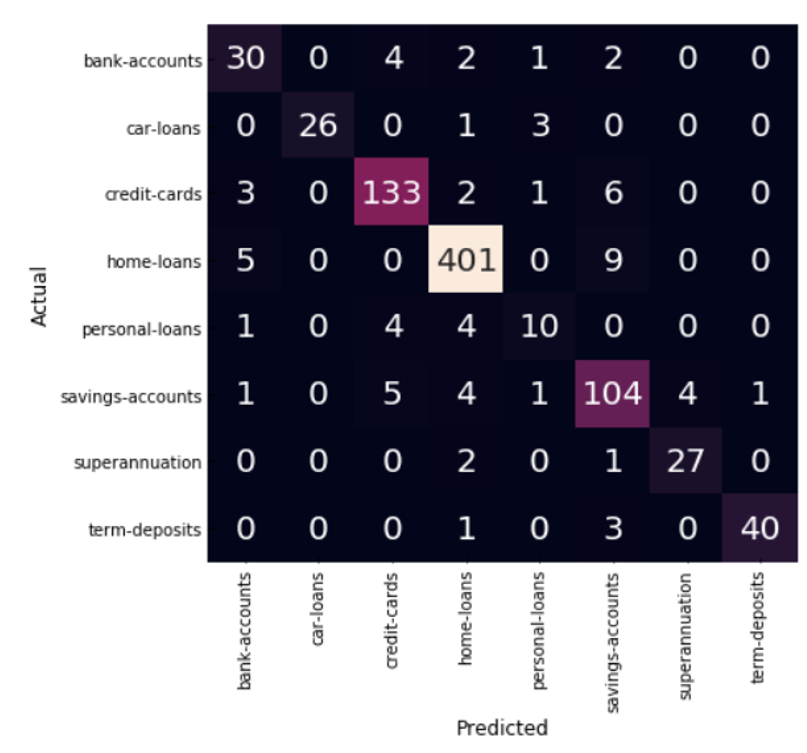
The diagonal is where the model got the predictions right.
If you look at the home-loans for example,
Out of the 415 home loan articles 9 were predicted as savings-accounts and 5 were predicted as bank-accounts.
I was pretty satisfied at this stage with the performance of my model.
Web-app
To see the model in action for my client, I built a web app using the flask,a micro web framework written in Python. The classifier model will run in the background
Snapshot of the app
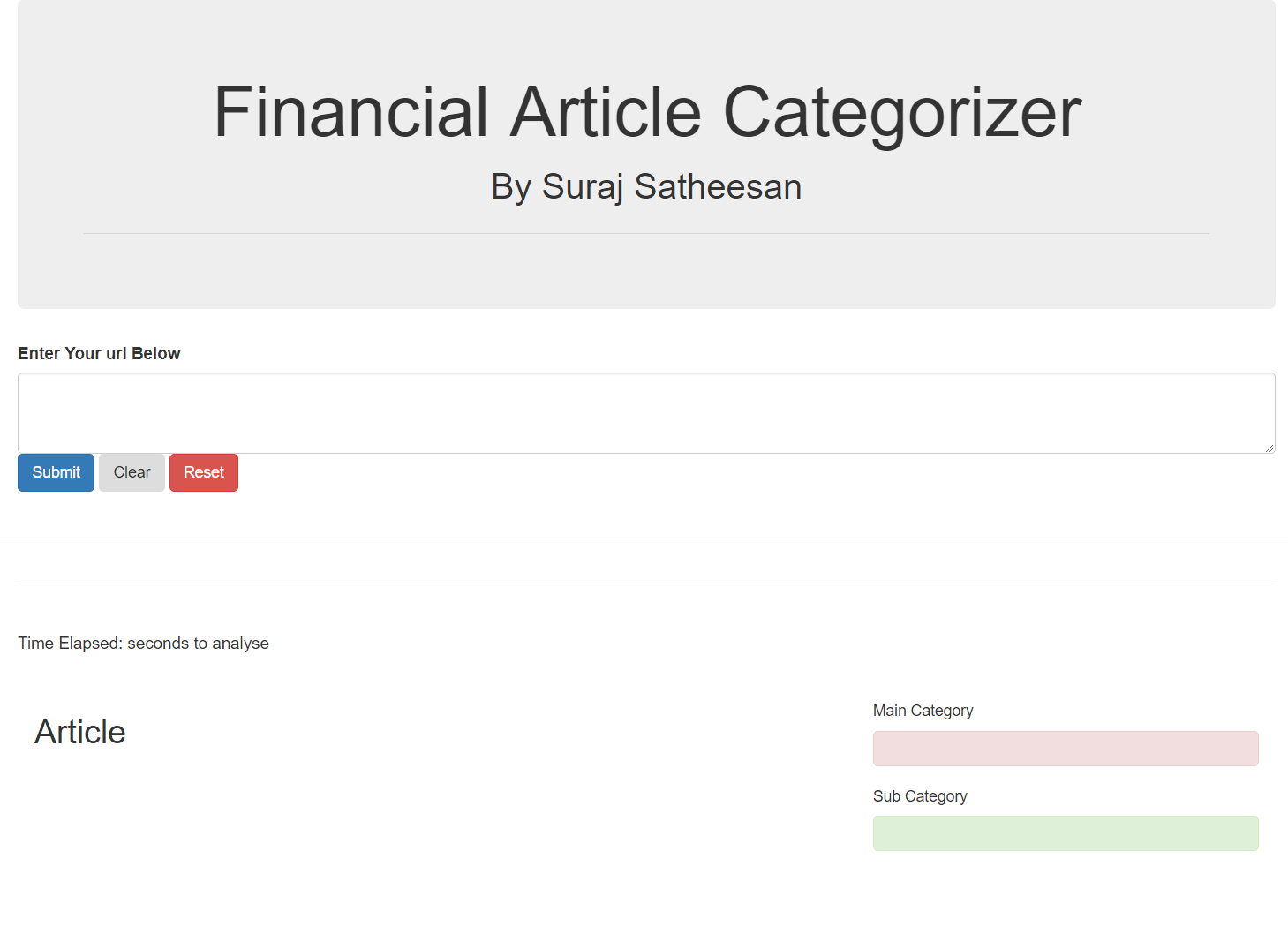
Just paste the link of the article in the text box. The article itself will come under Article and the prediction for the category will come in the red box.
Snapshot of the app after feeding it an article about real-estate

References
Project Source Code
For the Flask app
For this Blog site framework
NLP